DIE BEDEUTUNG DER GRUNDFREQUENZ FÜR DIE KLANGQUALITÄT UND DAS SPRACHVERSTEHEN
Autor: Simon Müller, M. Sc. in Audiology, Audiologisch-wissenschaftlicher Leiter, Widex Hörgeräte GmbH
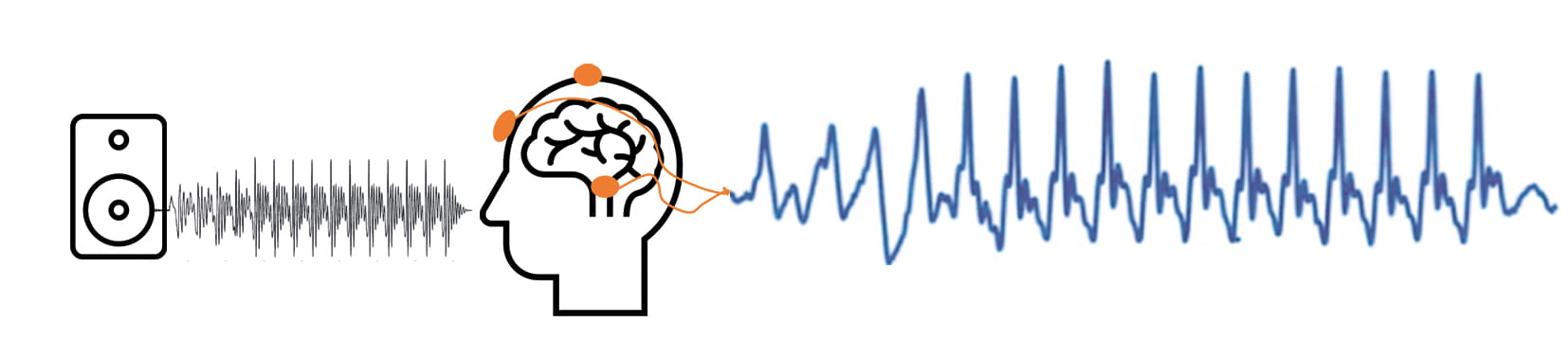
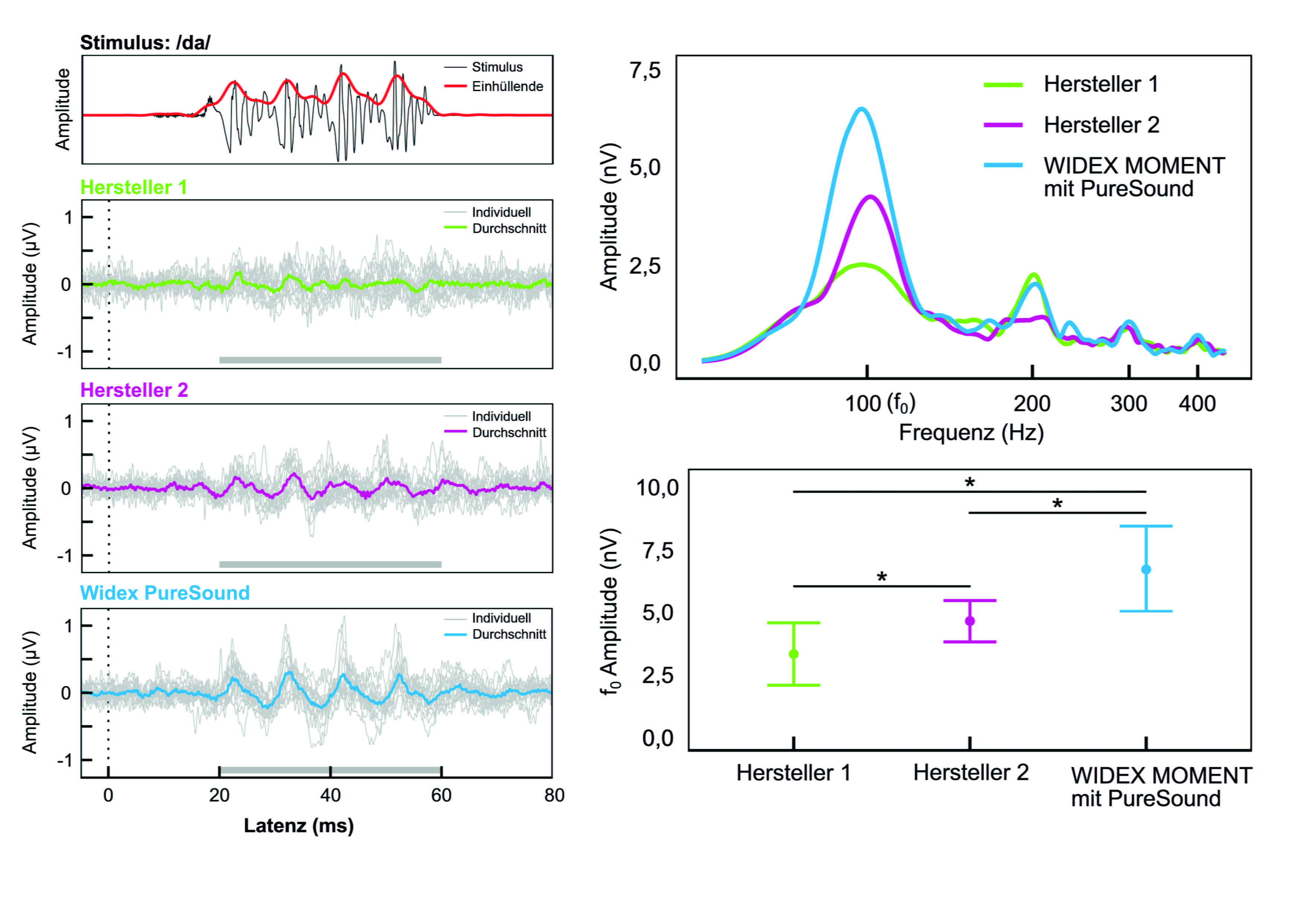
Für die subkortikale und kortikale Verarbeitung von akustischen Signalen berichten unterschiedliche Forschungsarbeiten wie wichtig eine neuronal stabile Verarbeitung der Grundfrequenz ist. Es gibt Hinweise auf einen Zusammenhang zwischen der neuronalen Bewahrung der Grundfrequenz und der Sprachverständlichkeit im Störgeräusch. So ist die Ableitung akustisch evozierter Potenziale auch für die Bewertung moderner Signalverarbeitungen in Hörsystemen von Bedeutung.
Zu fast jedem Zeitpunkt unseres Alltags befinden wir uns in der Gegenwart von komplexen Klängen. Egal ob es sich um die Stimme einer Sprecherin oder Sprechers, das Surren einer elektrischen Zahnbürste oder das Ertönen eines Musikinstruments handelt – dem menschlichen Gehirn gelingt es, diese Fülle an Informationen voneinander zu trennen und einzelnen Signalen eine Bedeutung zu geben. Als eine relevante Voraussetzung für die Bewältigung dieser Aufgaben gilt die Fähigkeit, die Grundfrequenz eines Signals neuronal abzubilden, also zu codieren. Der daraus resultierende neuronale Code wird weiterführend höhergelegenen kognitiven Prozessen zur Verfügung gestellt. Dieser Artikel bietet einen Überblick über den Zusammenhang zwischen der neuronalen Abbildung der Grundfrequenz und zusammenhängenden Eigenschaften wie der Sprachverständlichkeit oder Lokalisation. Des Weiteren wird beschrieben, wie die Ableitung akustisch evozierter Potenziale unter Verwendung komplexer Signale, wie der Silbe /da/, zur Bewertung moderner Hörsystem-Signalverarbeitungen herangezogen werden kann. Doch zunächst stellt sich die Frage, wie sich komplexe Klänge unseres Alltags spektral zusammensetzen.
Zusammensetzung komplexer Klänge
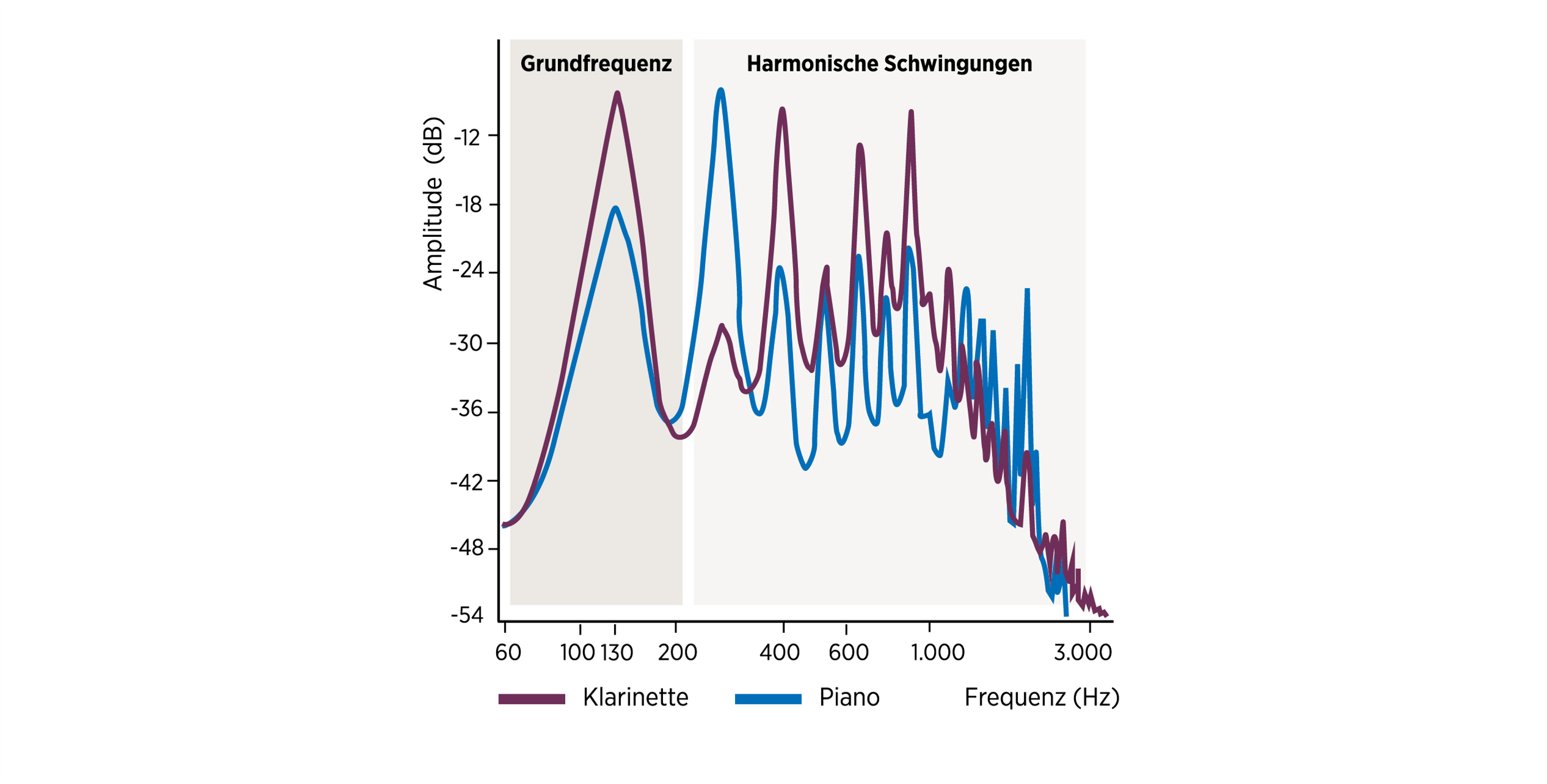
Anders als Reintöne beinhalten komplexe Klänge mehrere Schwingungskomponenten, also Sinuswellen. Diese umfassen die Grundfrequenz (F0) sowie deren dazugehörige harmonische Schwingungen. Während die Grundfrequenz die Wiederholungsrate eines Signals pro Sekunde repräsentiert, z. B. bei 130 Hz, sind die harmonischen Schwingungen das ganzzahlige Vielfache der Grundfrequenz. Sie liegen in diesem Beispiel folglich bei 260 Hz, 390 Hz, 520 Hz und so weiter. Zudem können die harmonischen Schwingungen eines komplexen Signals in ihrer Intensität je nach Schallquelle variieren. Das Ergebnis aus Phasen-Summation und -Auslöschung der einzelnen Bestandteile aus Grundfrequenz und harmonischen Schwingungen ergibt die komplexe Wellenform und bestimmt folglich den Klang.